Flashbacks of the year that I spent as a consultant with a cadre of operations researchers.
...well over a hundred parameters for one function call, with a mix of literal values and pointers being passed in.
Some of the parameter and type names are particularly frightening. a1alleles is not a name you want to read in Arial. And what of Oblig_missing_info* om_ip?
...the developer replied with a one line code fix:
i $$zRunAsBkgUser(desc_$H,"runReportBkg^KHUTILLOCMAP",$na(%ZeData)) d
. w !,"Search has been started in the background."
e w !,"Search failed to start in the background."
I'm working on a smallish project to build service endpoints using Slim. (We've used other frameworks in the past. I recently converted my model code to a PSR-4 autoloader. The team strongly suggested Slim for this project.)
The Slim documentation makes it abundantly clear that Response objects are immutable: each method that accepts a Response as an argument returns a copy of that object. You can also puzzle out that methods like withHeader() and withStatus() can be chained together. And the docs explain how to use withJson() if you want your endpoint's payload to be JSON and you're content with the default MIME type.
What is not so well explained: that getBody()->write()does not return a Response, so it can't be chained. Nor is it clear how to use these methods when you want to set your own MIME type ("application/hal+json", in my case) or status code. Hence, this example, somewhat simplified.
The GET /short endpoint returns a brief HAL representation of the resource identified by :id.
namespace Demo;
class Controller {
/**
* GET /short/:id
*
* @param \Slim\Http\Request $request
* @param \Slim\Http\Response $response
* @param string[] $args
* @return \Slim\Http\Response
*/
public function short($request, $response, $args) {
$id = $args['id'];
try {
$guid = ...; //look up info about $id
if (empty($guid)) {
Logger::warning("No info for $id");
return $response->withStatus(404);
}
$doc = ...; // construct a model, using $guid
$rsp = $response->withAddedHeader('Content-type', 'application/hal+json');
$rsp->getBody()->write(json_encode($doc->getDocArray()));
return $rsp;
}
catch (Exception $e) {
Logger::warning($e->getMessage()." Failed");
return $response->withStatus(500);
}
}
}
And how do you write a unit test for this endpoint? Likewise, the docs give some strong hints, but leave you to connect the dots. The trick is to use Environment::mock() to get an object that can be passed to a factory method on Request. A simplified version of my happy-path unit test:
class ControllerShortTests extends \PHPUnit_Framework_TestCase
{
/** @var \Slim\Http\Request */
private $request;
/** @var \Slim\Http\Response */
private $response;
/** @var string[] */
private $args;
/** @var \Slim\Container */
private $container;
/** @var \Demo\Controller */
private $controller;
public function setUp()
{
$this->request = \Slim\Http\Request::createFromEnvironment(\Slim\Environment::mock());
$this->response = new \Slim\Http\Response();
$this->args = [];
$this->container = new \Slim\Container();
... // set up a mock datastore provider
$this->controller = new \Demo\Controller($this->container);
}
public function testExpectSuccess()
{
... // configure the provider
$this->args['id'] = 987654321;
$response = $this->controller->short($this->request, $this->response, $this->args);
$this->assertEquals(200, $response->getStatusCode(), 'Wrong status');
... // and more assertions
}
}
Boerge Svingen walks us through the log-based architecture that powers digital publishing at the New York Times. Now that we are in the era where disk isn't just cheap, it's effectively free, a storage-heavy approach like this can make sense.
David Sleight provides some inside-baseball info about ProPublica's revamped mobile apps, including the yogic contortions required of this non-profit to satisfy Apple.
Jane Cotler and Evan Sandhaus describe two neat tricks that the New York Times used to bring a recent 20-year block of articles into its TimesMachine service. First, an image tiling and rendering procedure that minimizes download requirements. Even more interesting, a fuzzy-logic string-matching algorithm that lines up a batch of texts taken from OCR with their counterparts from a digital archive. The trick to reducing the search space depends on dividing each text into blocks of overlapping tokens called shingles, a/k/a n-grams.
Using regular expressions to crack the inconsistencies of a century-old bibliography and bring an important compendium of zoological taxonomy into the semantic web: Suzanne C. Pilsk et al., "Unlocking Index Animalium: From paper slips to bytes and bits."
My team is building its first application in the Apache Struts 2 framework (it's actually a migration from a Struts 1 application). So we already have a substantial suite of actions already coded, organized into modules. The Struts 2 package concept handles our modules well.
We have standard logic that we want to execute for the invocation of any action (authentication, logging, timing, etc.), so I've recoded our Struts 1 filters as interceptors.
Then there is exception handling. It took me several readings of the documentation and various forum postings and some trial and error to get this working the way we need it, including being able to catch exceptions thrown by interceptors. I ended up deciding to pass the exception info directly to a view JSP, rather than an action class, but we might revisit that decision and do some refactoring.
The docs explain how to configure a handler to be applied globally to the entire application, and how to configure an action-specific handler. But in our case, we have one module that consists of actions that respond to Ajax requests, and hence render JSON, while the other modules render complete web pages with JSPs. The problem statement: how can you configure a Struts 2 global exception handler with the <global-exception-mapping> tag that will apply to a specific package, but will share the same interceptor stack with the rest of the application? For actions in our JSON module, we want error info returned as JSON payload, not HTML.
Well, it turns out that you can do it, but you have to be a little creative with the package inheritance hierarchy. What follows is a simplified (and slightly redacted) version of our actual application, so I can't vouch that this code is complete and accurate, but it should give you the general idea.
The key is to make a package just for the interceptors. Then every other package extends that package. The core package defines exception handlers and global results that all packages use, except the json package, which defines its own.
Here's the struts.xml (again, in our production solution, every package is defined in a separate file that is brought in with <include>, but it's easier to see what's going on with everything in one place):
Notice that we use <global-results> to account for results returned by interceptors, as well as the exception handling mechanism.
I consider it a blot that you have to define <global-results> in two places, in both the core and json packages, but that's apparently what you have to do.
I recommend creating a tracer interceptor as part of your tool kit. All that it does log a message (here, set as a configurable parameter). Writing the code is a good tutorial for creating your first interceptor from scratch, and once you've got it, you can use it to debug your interceptor stacks. I've only shown one stack in this example, but when your requirements call for alternative stacks, it's good to know that you're executing the one you want.
My colleagues Patrick Cooper and Scott Stroud talk to Ethan Marcotte and Karen McGrane about our approach to responsive web design and how we use agile techniques to get projects done.
This project has also given us the chance to really think about our products in general, and not just thinking about the website, or the mobile site, but also thinking about our overall digital products. The product is companionship. How do we become a better companion to people?
To sort through the massed tangle of conflicting requirements and desiderata, the team did the Agile thing: It put Post-It notes on a wall and called back the users to identify features that fit these criteria. Did the feature contribute directly to getting the president reelected? And would it be needed in 12 weeks...?
We follow Adobe's recommendation to use the tag structure to represent menu navigation. Thus, pages can be organized in the content tree the way that is convenient for authors to work (or perhaps to enforce some design restrictions by template), while menus can evolve flexibly in response to usability testing or can differ depending on platform (desktop vs. mobile).
So to render a menu, it's a typical coding pattern to walk a subtree of tags, and for each one, find its corresponding web page (Node) and render its hyperlink. The only tricky bit is that com.day.cq.tagging.Tag.find() returns both Nodes that are explcitly marked with the specified tag as well as Nodes that are only subordinate to a Node that is assigned the tag. A lot of the time, you just want Nodes of the first kind.
We had been using a scheme that matched the Node's navigation title to the tag's title, but that pattern broke down when authors started designing menu items with duplicate names. (And there were other wrinkles.) So, after some desperate Friday afternoon whiteboard sketching, I realized that we could inquire of each candidate Node what tags were assigned to it explicitly, and test for an exact match of TagIDs. And I cooked up the following method, stripped of exception handling, debugging logic, and a little project-specific stuff. The cq:tags property is multi-valued, so there's a little more messy object navigation than you might expect.
import com.day.cq.tagging.Tag;
import java.util.Iterator;
import javax.jcr.Node;
import javax.jcr.Property;
import javax.jcr.PropertyIterator;
import javax.jcr.Value;
import org.apache.sling.api.resource.Resource;
* * *
/**
* Returns the node tagged with the specified tag; if there is more than one such node, returns
* one of them arbitrarily. The node must have the tag assigned directly to it as a property;
* nodes that are tagged by inheritance in the content tree are ignored.
* @param tag
* @return node: the node tagged with the specified tag, or null
*/
public static Node getMatchingNode(Tag tag) {
Node matchingNode = null;
Iterator<Resource> relatedNodes = tag.find();
outer:
while (relatedNodes.hasNext() && matchingNode == null) {
Node node = relatedNodes.next().adaptTo(Node.class);
PropertyIterator tagIds = node.getProperties("cq:tags");
while (tagIds.hasNext()) {
Property property = tagIds.nextProperty();
Value values[] = property.getValues();
for (Value value : values) {
String id = value.getString();
if (id.equals(tag.getTagID())) {
matchingNode = node;
break outer;
}
}
}
}
return matchingNode;
}
The code examples provided by Adobe for CQ5 developers are fine so far as they go. But I found myself exploring the territory without a map when I started prototyping code to perform a bulk import (from a legacy CMS, in my case). So I put together this toy class; it inserts a content page and text (as a parsys) at an arbitrary position in the content hierarchy.
I wrapped this functionality into a workflow process step, but it ought to work perfectly well as part of a command-line program, too. The advantage of making it a process step is that you get a session established for you, and the navigation to the insert point has been taken care of. (I haven't yet explored developing for CQ5 with standalone programs).
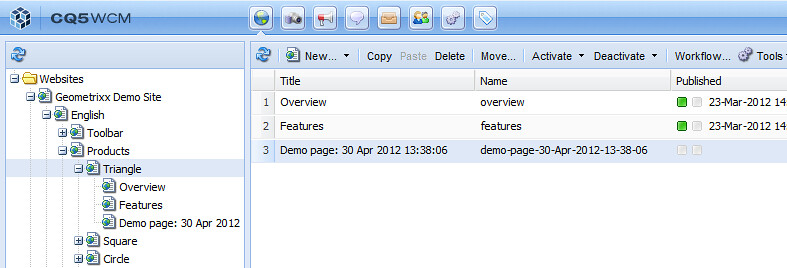
I created a workflow model that uses this process step, then I created an instance of the model and ran it, specifying the English > Products > Triangle page from the Geometrixx web site as the payload.
Here's the code, sanitized to remove client names and a little condensed. I'm using version 5.4.
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.io.Reader;
import java.text.SimpleDateFormat;
import java.util.Date;
import javax.jcr.Node;
import javax.jcr.RepositoryException;
import org.apache.sling.jcr.resource.JcrResourceConstants;
import org.apache.felix.scr.annotations.Component;
import org.apache.felix.scr.annotations.Properties;
import org.apache.felix.scr.annotations.Property;
import org.apache.felix.scr.annotations.Service;
import org.osgi.framework.Constants;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.day.cq.workflow.WorkflowException;
import com.day.cq.workflow.WorkflowSession;
import com.day.cq.workflow.exec.WorkItem;
import com.day.cq.workflow.exec.WorkflowData;
import com.day.cq.workflow.exec.WorkflowProcess;
import com.day.cq.workflow.metadata.MetaDataMap;
import com.day.cq.wcm.api.NameConstants;
@Component
@Service
@Properties({
@Property(name = Constants.SERVICE_DESCRIPTION,
value = "Makes a new tree of nodes, subordinate to the payload node, from the content of a file."),
@Property(name = Constants.SERVICE_VENDOR, value = "Siteworx"),
@Property(name = "process.label", value = "Make new nodes from file")})
public class PageNodesFromFile implements WorkflowProcess {
private static final Logger log = LoggerFactory.getLogger(PageNodesFromFile.class);
private static final String TYPE_JCR_PATH = "JCR_PATH";
* * *
public void execute(WorkItem workItem, WorkflowSession workflowSession, MetaDataMap args)
throws WorkflowException {
//get the payload
WorkflowData workflowData = workItem.getWorkflowData();
if (!workflowData.getPayloadType().equals(TYPE_JCR_PATH)) {
log.warn("unusable workflow payload type: " + workflowData.getPayloadType());
workflowSession.terminateWorkflow(workItem.getWorkflow());
return;
}
String payloadString = workflowData.getPayload().toString();
//get the file contents
String lipsum = null;
try {
BufferedReader is = new BufferedReader(new FileReader("e:\\Sandbox\\CQ5\\content.html"));
lipsum = readerToString(is);
}
catch (IOException e) {
log.error(e.toString(), e);
workflowSession.terminateWorkflow(workItem.getWorkflow());
return;
}
//set up some node info
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("d-MMM-yyyy-HH-mm-ss");
String newRootNodeName = "demo-page-" + simpleDateFormat.format(new Date());
SimpleDateFormat simpleDateFormatSpaces = new SimpleDateFormat("d MMM yyyy HH:mm:ss");
String newRootNodeTitle = "Demo page: " + simpleDateFormatSpaces.format(new Date());
//insert the nodes
try {
Node parentNode = (Node) workflowSession.getSession().getItem(payloadString);
Node pageNode = parentNode.addNode(newRootNodeName);
pageNode.setPrimaryType(NameConstants.NT_PAGE); //cq:Page
Node contentNode = pageNode.addNode(Node.JCR_CONTENT); //jcr:content
contentNode.setPrimaryType("cq:PageContent"); //or use MigrationConstants.TYPE_CQ_PAGE_CONTENT
//from com.day.cq.compat.migration
contentNode.setProperty(javax.jcr.Property.JCR_TITLE, newRootNodeTitle); //jcr:title
contentNode.setProperty(NameConstants.PN_TEMPLATE,
"/apps/geometrixx/templates/contentpage"); //cq:template
contentNode.setProperty(JcrResourceConstants.SLING_RESOURCE_TYPE_PROPERTY,
"geometrixx/components/contentpage"); //sling:resourceType
Node parsysNode = contentNode.addNode("par");
parsysNode.setProperty(JcrResourceConstants.SLING_RESOURCE_TYPE_PROPERTY,
"foundation/components/parsys");
Node textNode = parsysNode.addNode("text");
textNode.setProperty(JcrResourceConstants.SLING_RESOURCE_TYPE_PROPERTY,
"foundation/components/text");
textNode.setProperty("text", lipsum);
textNode.setProperty("textIsRich", true);
workflowSession.getSession().save();
}
catch (RepositoryException e) {
log.error(e.toString(), e);
workflowSession.terminateWorkflow(workItem.getWorkflow());
return;
}
}
}
Here's the comp text in e:\\Sandbox\\CQ5\\content.html:
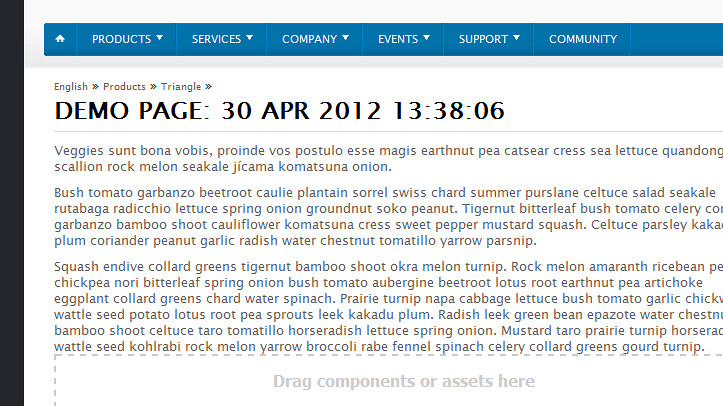
Veggies sunt bona vobis, proinde vos postulo esse magis earthnut pea catsear cress sea lettuce quandong scallion rock melon seakale jícama komatsuna onion.
Bush tomato garbanzo beetroot caulie plantain sorrel swiss chard summer purslane celtuce salad seakale rutabaga radicchio lettuce spring onion groundnut soko peanut. Tigernut bitterleaf bush tomato celery corn garbanzo bamboo shoot cauliflower komatsuna cress sweet pepper mustard squash. Celtuce parsley kakadu plum coriander peanut garlic radish water chestnut tomatillo yarrow parsnip.
Squash endive collard greens tigernut bamboo shoot okra melon turnip. Rock melon amaranth ricebean pea chickpea nori bitterleaf spring onion bush tomato aubergine beetroot lotus root earthnut pea artichoke eggplant collard greens chard water spinach. Prairie turnip napa cabbage lettuce bush tomato garlic chickweed wattle seed potato lotus root pea sprouts leek kakadu plum. Radish leek green bean epazote water chestnut bamboo shoot celtuce taro tomatillo horseradish lettuce spring onion. Mustard taro prairie turnip horseradish wattle seed kohlrabi rock melon yarrow broccoli rabe fennel spinach celery collard greens gourd turnip.
Here's what the Websites window looks like after execution:
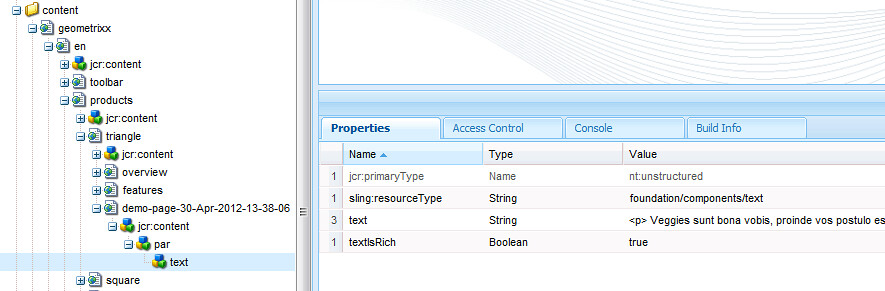
Here's what the corresponding node looks like in CRXDE Lite:
And here's what the page looks like in the content finder:
Some notes about the demonstrator code:
I like to use lorem ipsum-style text (I got this text from Veggie Ipsum) when I'm testing. It's always clear that you're using test data rather than a copy of something live. And in the unlikely event that your test data leaks into production, it's a lot less embarrassing to see "lorem ipsum" than "asdf jkl; asdf jkl;" or "yo mama" in 16-point type, in my opinion.
I incorporated a timestamp into the name and title of the content page to be inserted. That way, you can run many code and test cycles without cleaning up your repository, and you know which test was the most recently run. Added bonus: no duplicate file names, no ambiguity.
Adobe and Day have been inconsistent about providing constants for property values, node types, and suchlike. I used the constants that I could find, and used literal strings elsewhere.
I did not fill in properties like the last-modified date. In code for production I would do so.
I found myself confused by Node.setPrimaryType() and Node.getPrimaryNodeType(). The two methods are only rough complements; the setter takes a string but the getter returns a NodeType with various info inside it.
Sometimes a photo of a whiteboard isn't such a creative, cheerful thing. The horror! the horror! As clear as I can read, one of the tables in this query is called BEST_MURDER.
We support a number of different question types in our surveys. As a questionnaire designer, you can ask a question that has to be answered with a number, or with a date. Or you can ask for a long free-text answer: EFM Community calls this an "essay question." But the predominant question types are two: Choose One and Choose Many. (Older versions of EFM Feedback called these Single Select and Multiple Select.) These questions can be asked either one-by-one or grouped into tables or matrices. Maybe 80% of the questions asked in deployed surveys are either Choose One or Choose Many.
A Choose One question is usually rendered with radio buttons, though sometimes designers use a dropdown.
What is your favorite color?
Red Orange Yellow Green Blue
While a Choose Many (a/k/a Choose All That Apply) uses checkboxes.
What Metro line(s) do you ride regularly?
Red OrangeYellow Green Blue
These two question types look to be so similar, and yet there are subtle differences in the way the data for them is collected and analyzed, and I've seen more than one analyst stumble over the differences.
Let's say that you're architecting an application that lets people design and administer surveys. What are the pitfalls? Here I'm focusing on how to model the actual survey responses that are collected, rather than how to model the metadata that constitutes the survey design.
A single database attribute is sufficient to store the respondents' answers to a Choose One. For our example question above, assign the values 1 through 5 to the five color choices. Then you can store the survey respondents' answers in a relational database column typed as an integer of some suitable size, 8 or 16 bits, perhaps. It depends on how many possible choices you want to provide for in your survey software app.
On the other hand, for a Choose Many, you need as many database attributes as there are possible choices. One way to do it is to use one boolean database column for each choice: five columns in our example above. Or you could pack the answers into a bitfield, although querying and filtering on individual choices would then be a problem. Whatever path you take as the software architect, the key point is that the respondents' answers will be represented differently than for Choose One questions.
Generally, Choose Ones are just easier to deal with—a generic design is more accommodating. This fact probably explains why almost all of the free online polls that you see (hosted by outfits like polldaddy) are Choose Ones.
If your survey app allows designers to change a survey's design by adding more choices after the survey has been released to the world, you can see that adding a choice to a Choose One (just another possible value to be stored) is a lot simpler than adding a choice to a Choose Many (maybe a new database column).
What is your favorite color?
Red Orange Yellow Green Blue Indigo Violet
What Metro line(s) do you ride regularly?
Red Orange Yellow Green Blue Silver Purple
Even trickier is enabling a survey designer to rewrite a Choose One as a Choose Many, or vice versa.
What are your favorite color(s)?
Red Orange Yellow Green Blue
What Metro line do you ride most often?
Red Orange Yellow Green Blue
In this case, you're not simply extending a relational schema by adding columns or possible values, but rather you've got to convert one column type to another.
Reporting and analyzing survey responses for the two question types is likewise different.
For Choose One questions, you can do a frequency analysis that adds up to 100%:
What is your favorite color? (N of respondents=100)
45% Red
12% Orange
10% Yellow
17% Green
16% Blue
And if your corresponding numerical scale makes sense, you can compute means and other statistics. (Granted, this makes more sense for computing something like average customer satisfaction than for computing an average favorite color.) Analysis like this can be presented effectively with a pie chart.
But for Choose Many questions, the numbers never add up.
What Metro line(s) do you ride regularly? (N of respondents=100)
45% Red
22% Orange
65% Yellow
22% Green
40% Blue
An unstacked bar chart is probably the best way to present this information graphically. At least you can depend on the longest/tallest bar being no more than 100%. Also notice that you don't have a numerical scale, just booleans, so you can't compute means and standard deviations for Choose Many questions.
I haven't delved into some of the more fiddly bits of designing a survey app that supports Choose One and Choose Many questions. Things like support for "none of the above," "I don't know," "not applicable to me," or "I'd rather not say" choices, or requiring that the respondent check at least one box or radio button, or at most three checkboxes.